Organização Estruturada de Computador
- Aula 3
Nesta aula será apresentada uma visão geral do funcionamento
do processador de um computador
O texto abaixo é um resumo das seções 2.1 e
2.1.1 a 2.1.6 do capítulo 2 do lívro: Organização
Estruturada de Computadores de Andrew S. Tanenbaum, 4a Edição,
2001.
Importante: O resumo abaixo deve ser complementado, pelo
aluno, com a leitura do texto original do livro.
Tópicos
Processadores
Organização geral de um computador:
processador + memória principal + periféricos de E/S
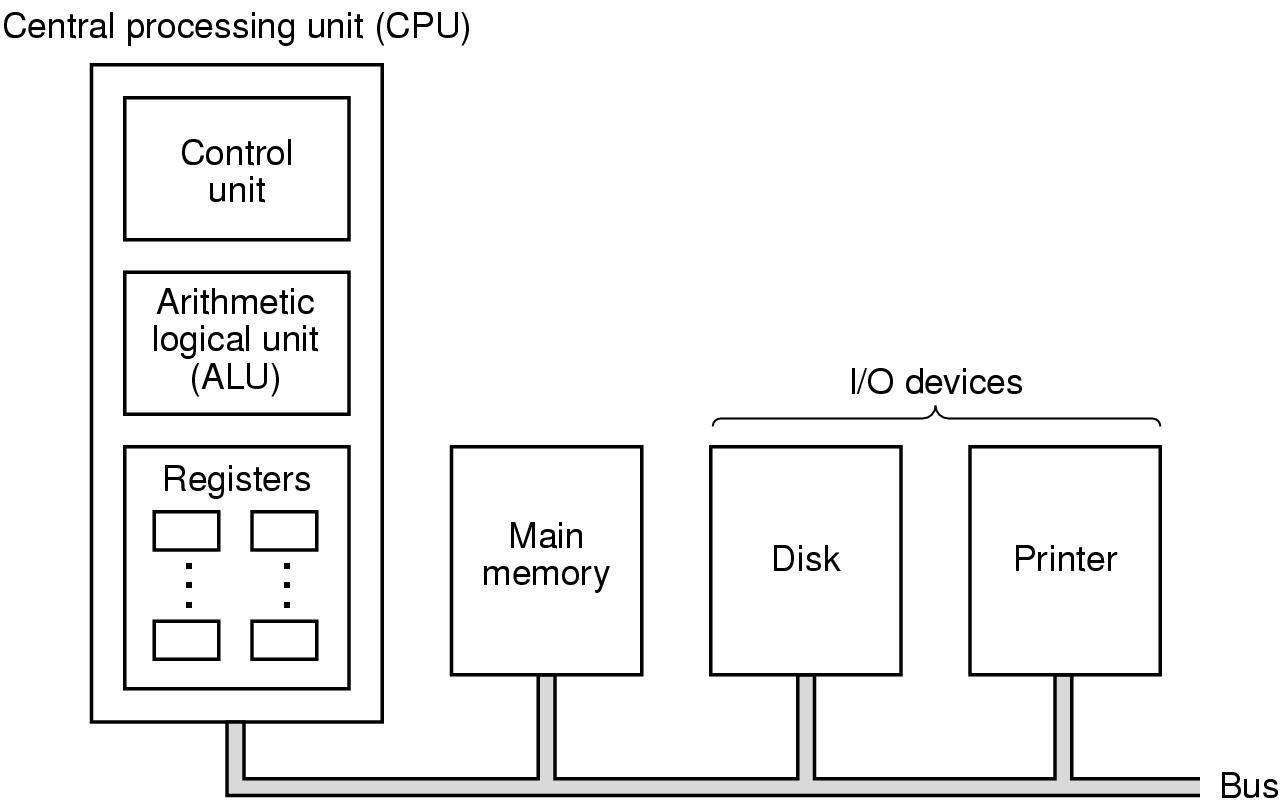
Figura 2-1: Organização de um computador muito simples, com
1 processador e 2 dispositivos de E/S
O processador é o "cérebro" do
computador.
Sua função é executar os
programas armazenados na memória principal. O processador busca cada
instrução na memória, examina-a e executa uma após
outra.
Barramentos: Os componentes de um computador
são ligados por barramentos
- conjunto de fios paralelos que permite a transmissão de dados,
endereços, sinais de controle e instruções
- existem barramentos internos e externos ao processador
Componentes de um processador: (ver figura 2-1)
- Unidade de Controle: busca e define o tipo de cada instrução
- Unidade Aritmética Lógica (UAL): realiza
as operações necessárias a execução das
instruções
- Registradores:
- memória pequena de alta velocidade
- em geral todos de tamanhos iguais
- Program Counter (PC): armazena o endereço da próxima
instrução
- Registrador de Instruções (IR): armazena instrução
que está sendo executada
- Outros registradores de propósito geral ou específico
Organização do Processador
:
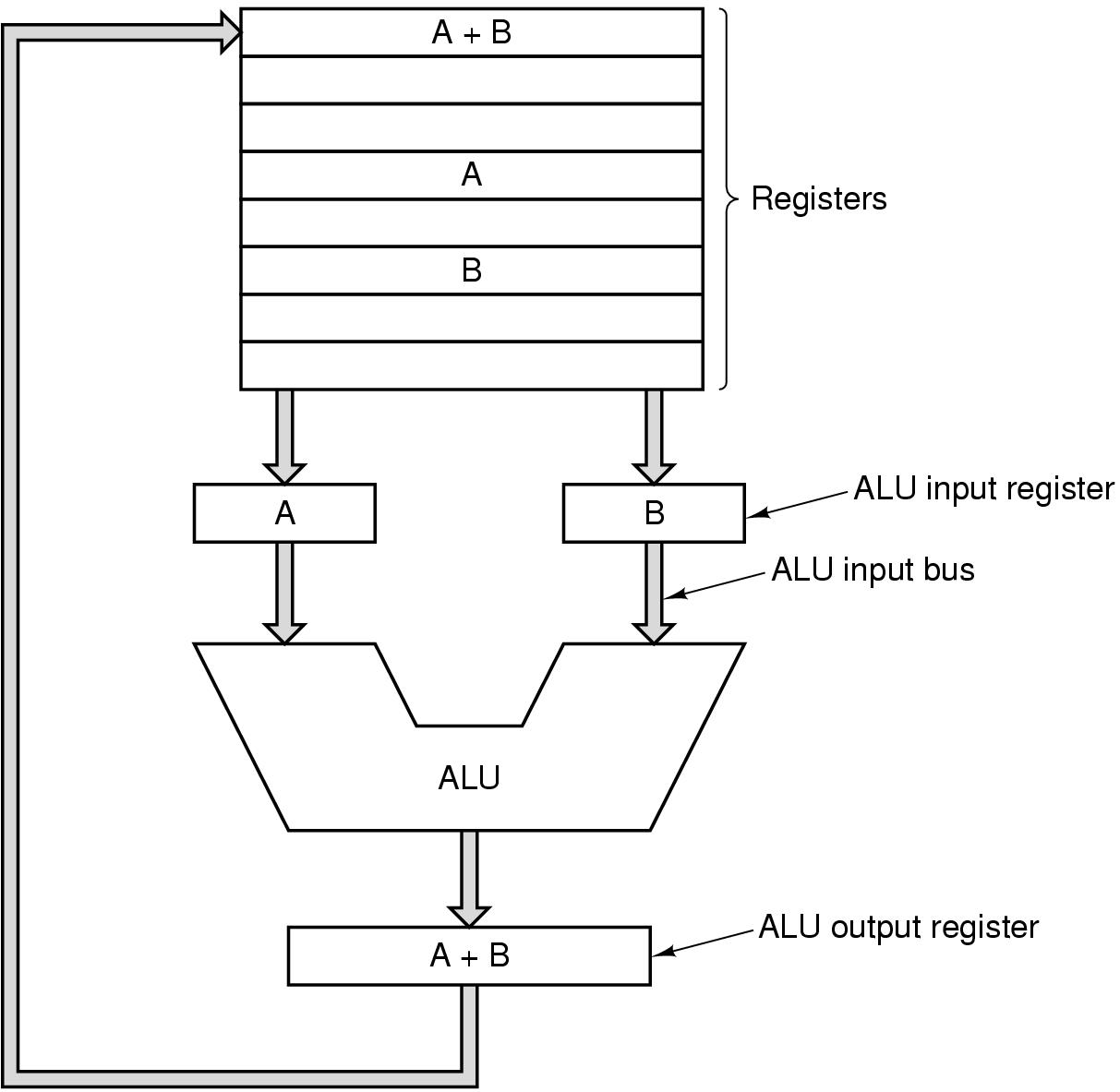
Figura 2-2: Caminho de dados para uma máquina típica
de Von Neumann.
Caminho de dados:
- Parte do processador com registradores (1 a 32), UAL e barramentos
- Dois registradores armazenam as duas entradas (A e B) da UAL
- A saída da UAL é conectada a 1 dos registradores
- Existem 2 classes de instruções:
- instrução registrador-memória: que permite
que uma palavra de memória seja armazenada no registrador,
e vice-versa
- instrução registrador-registrador: instrução
que opera sobre 2 registradores e coloca a saída em outro registrador
(ciclo de caminho de dados)
Importante: A velocidade do caminho de dados
determina a velocidade do computador
.
Execução de Instruções
(pelo processador)
Ciclo de Busca-Decodificação-Execução
de 1 instrução
1. Busca próxima instrução na memória
e armazena no IR
2. Atualiza Contador de instrução PC para
apontar para a próxima instrução
3. Determina tipo de instrução armazenada
no IR
4. Determina endereço dos dados na memória,
se a instrução requer dados adicionais
5. Busca palavras (dados) na memória, caso a instrução
precisar, e armazena-as em outros registradores
6. Executa instrução
7. Volta ao passo 1
Ver Figura 2.3 - Interpretador de
procedimento JAVA
Observações
- O interpretador de JAVA simula a função de 1 processador
- Programa JAVA: executado por interpretação, hardware
ou híbrido (hardware + software)
Compatibilização entre famílias
de computadores
Problema 1: Como construir computadores
de baixo custo capaz de executar todas as instruções complexas
de máquinas de alta performance, muito mais caras?
- Uma implementação em hardware puro (sem interpretação)
é usada somente nos computadores mais caros
- Uma implementação com interpretador de instrução
(por software) é usado em computadores mais baratos.
Vantagens do interpretador em
relação ao hardware puro
- Capacidade de corrigir no campo eventuais erros na implementação
de instruções
- Oportunidade de incorporar novas instruções nas máquinas
já existentes
- Projeto estruturado que permite o desenvolvimento, teste e documentação
de instruções complexas de maneira muito eficiente. Pode inclusive
substituir implementações antigas de instruções
- Armazenamento das microinstruções do interpretador
em memórias read-only (ROM), chamadas de memória de controle,
muito mais rápidas do que as memórias convencionais.
Problema 2: O uso da interpretação
permitiu a criação de um conjunto grande de instruções
() de importância discutível e que eram difíceis
e caras para serem implementadas diretamente por hardware (circuitos muito
complexos).
RISC versus CISC
RISC - Reduced
Instruction Set Computer
- Nova tecnologia para máquinas de alta performance (não
havia preocupação com compatibilidade)
- Máquina com conjunto reduzido de instruções
básicas em hardware (~50 instruções)
- Uso de chips processadores VLSI (Very Large Scale Integration) sem
interpretação
- Demais instruções eram geradas por combinação
das instruções básicas de hardware
CISC - Complex Instruction Set
Computer
- Tecnologia mais antiga e usada para famílias de computadores
compatíveis a nível de software.
- Número maior de instruções (~ 200 a 300
instruções)
- Uso extensivo de interpretação (principalmente para
modelos + baratos)
Argumento: Mesmo que uma máquina RISC precisasse
de 4 ou 5 instruções para fazer o que uma maquina CISC faria
com apenas 1 instrução, se a instrução RISC fosse
10 vezes mais rápida (só hardware) a máquina RISC vencia.
Questão: Porque então a tecnologia RISC não
suplantou a CISC ?
- Problemas de compatibilidade com máquinas antigas com software
já desenvolvido
- Aparecimento de soluções híbridas: Por exemplo,
a INTEL usa RISC para instuções de uso mais frequentes (Núcleo
RISC) e intepretação para instruções mais
complexas e de uso menos frequentes.
Princípios de Projeto para Computadores
Modernos
Princípios do projeto RISC que os arquitetos de
processadores de propósito geral devem seguir:
- Todas as intruções são diretamente executadas
por hardware
- Não existe o nível de microinstrução
- Para máquina com filosofia CISC as instruções,
em geral menos frequentes, que não existem em hardware são interpretadas
- Maximizar a Taxa à qual as instruções são
executadas
- Uso de paralelismo: execução de várias instruções
lentas ao mesmo tempo
- Execução de instruções não
precisa seguir a lógica da programação
- As instruções precisam ser facilmente decodificadas
- decodificação influencia na velocidade de execução
das instruções
- decodificação determina os recursos a serem usados
na execução das instruções
- quanto menor o número de formatos, mais fácil a
decodificação
- Somente as Instruções de Load e Store devem referenciar
a Memória
- Acesso a memória é mais lento
- Instruções que acessam a memória podem ser
intercaladas com outras instruções
- Projetar uma máquina com muitos registradores (>= 32)
- Palavras de memória devem permanecer nos registradores
o maior tempo possível
- Falta de registradores pode obrigar a buscar varias vezes a mesma
palavra da memória
Observação: Outras soluções
Existe limite tecnológico para desenvolvimento do hardware do chip
de processamento que depende do estado da arte da tecnologia.
Solução para aumentar a velocidade do processador: Uso de
paralelismo.
- a nível de instrução: 1 único processador
deve executar mais instruções por segundo
- a nível de processadores: vários processadores
trabalhando juntos na solução do mesmo problema
Paralelismo ao Nível de Instruções
Maior gargalo para a velocidade de execução
de instruções é o acesso a memória
Execução em Pipeline
O processamento em pipeline divide a execução
de instruções em várias partes, cada uma das quais tratada
por um hardware dedicado exclusivamente a ela.
Funcionamento de um pipeline de 5 estágios
- O estágio 1 busca a instrução da memória
e armazena num buffer até chegar a hora de executa-la
- No estágio 2 ocorre a decodificação da instrução,
determinando tipo e operandos
- No estágio 3 ocorre a busca dos operandos na memória
ou nos registradores
- No estágio 4 temos a execução - passagem pelo
caminho de dados
- No estágio 5 o resultado do processamento é escrito
num registrador
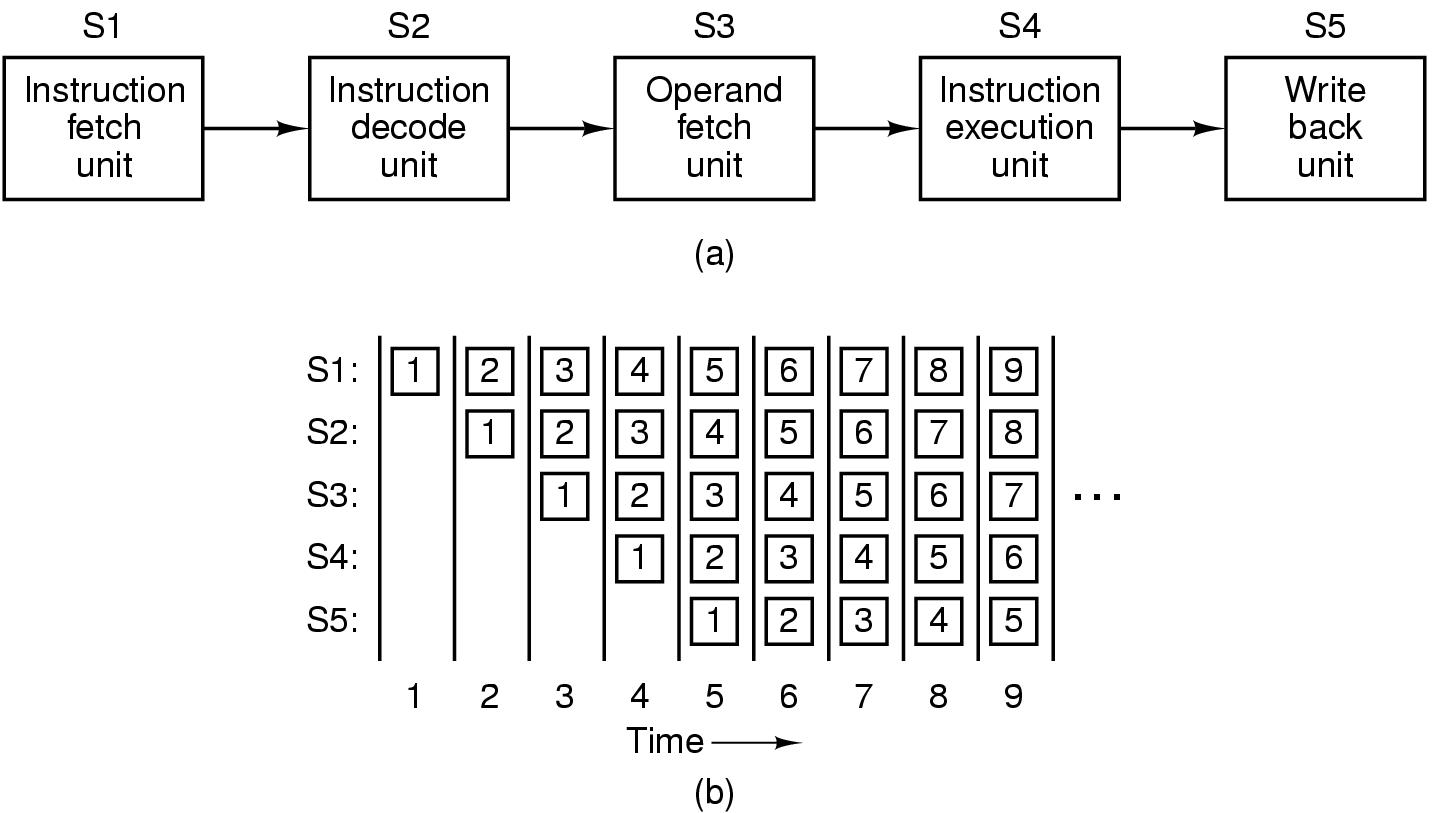
Figura 2-4: (a) Pipeline de 5 estágios. (b) Estado de cada um dos
estágios como função do tempo. Estão ilustrados
nove períodos de clock.
A idéia básica do pipeline é a mesma
de uma linha de produção em série. Vários processamentos
estão sendo executados ao mesmo tempo.
A Figura 2.4 mostra o funcionamento do pipeline mostrando
que os estágios de cada processamento são aplicados a várias
instruções ao mesmo tempo. Por exemplo: no tempo 1 a instrução
1 está sendo lida, no tempo 2 a instrução 1 está
sendo decodificada enquanto que a instrução 2 está sendo
lida, no tempo 3 a instrução 1 está buscando dados, a
instrução 2 estás sendo decodificada e a instrução
3 está sendo lida, e assim por diante.
Arquiteturas Superescalares
Se um pipeline é bom, com certeza dois serão
ainda melhor. (Veja figura 2.5)
Neste caso, uma única unidade de busca de instruções
lê 2 instruções e coloca cada uma em 1 pipeline
A execução dessas instruções
é feita em paralelo e:
- não pode haver conflitos pelo uso de recursos (mesmo registro,
por exemplo)
- o resultado de uma instrução não pode depender
do resultado da outra
- pode se pensar em pipelines com leitura inicial de 3 ou mais instruções
porém hardware fica complexo.
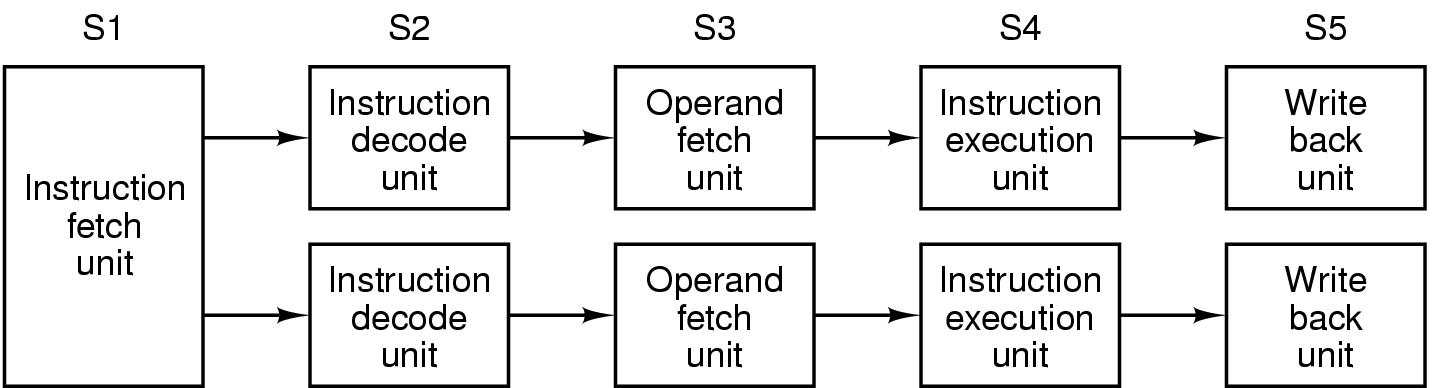
Figura 2-5. Dois pipelines de 5 estágios com uma unidade de busca
de instruções comum a ambos.
Máquinas de alta performance usam outra metodologia,
a arquitetura Superescalar
A idéia básica é ter um único
pipeline, com diversas unidades funcionais (Veja Figura 2.6)
O estágio 3 pode distribuir instruções
a uma velocidade consideravelmente mais alta do que o estagio 4 pode executá-las.
Este estágio usa vários dispositivos de hardware (inclusive
mais do que uma UAL) para acelerar o processamento neste estágio.
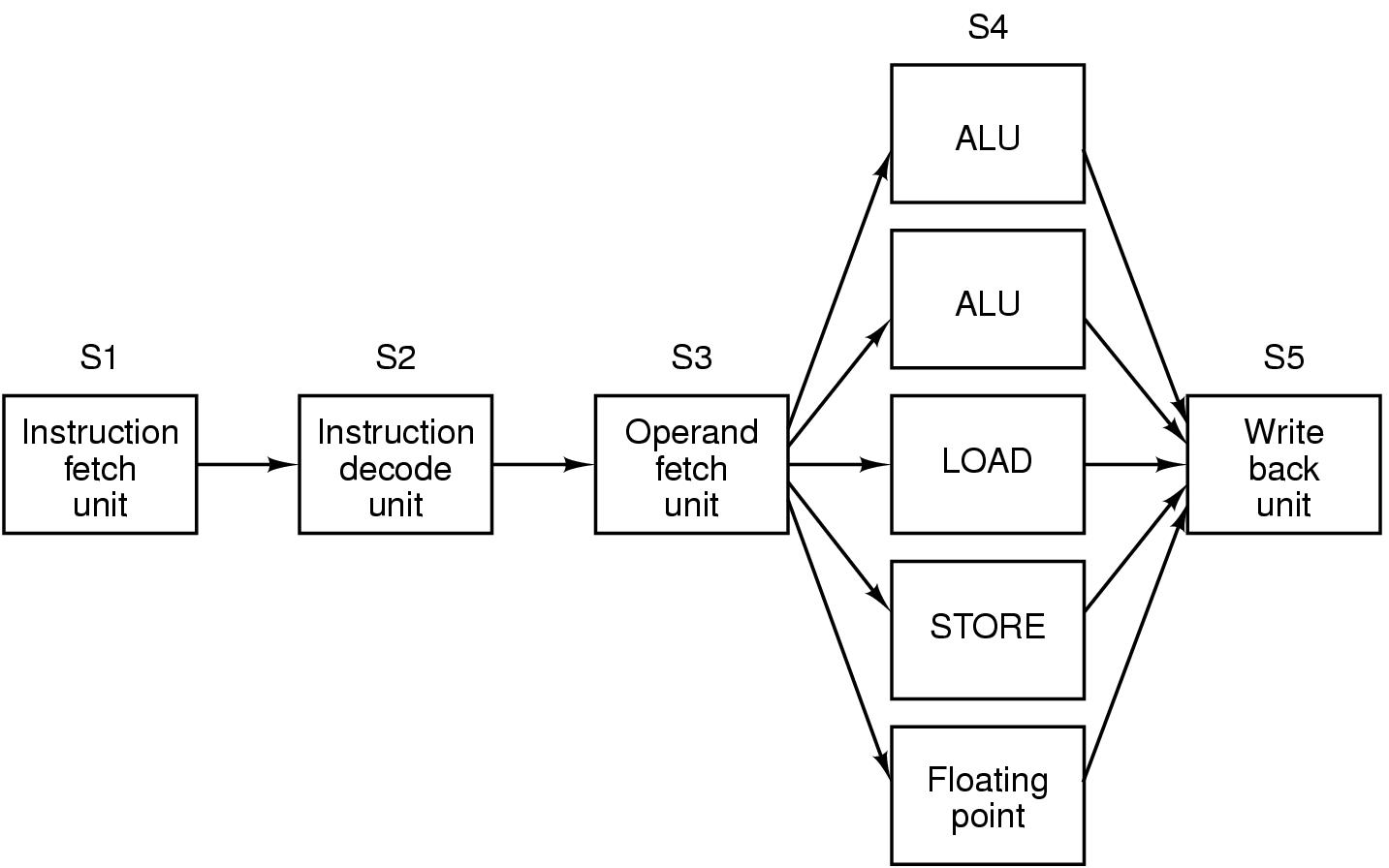
Figura 2.6 Processador superescalar com 5 unidades funcionais
Paralelismo ao Nível do Processador
A medida que os processadores vão ficando
mais rápido:
- aparecem limitações de ordem física (velocidade
da luz em fios de cobre ou fibras opticas)
- maior produção de calor pelo chip (problema para dissipar
essa energia)
Operação do processador em pipeline
ou em superescalar possibilita ganhos de 5 a ~10 vezes
Para ganhos maiores, 50-100 ou mais vezes, deve-se
projetar computador com mais de 1 processador
Computadores Matriciais (2 implementações)
- Processador matricial (veja figura 2.7)
- composto de grande número de processadores idênticos
- cada processador executa a mesma sequência de instruções
sobre diferentes conjuntos de dados
- tem uma única unidade de controle
- tem uma UAL para cada processador
- Processador vetorial
- muito parecido com processador matricial
- operações aritméticas são executadas
numa única UAL, que opera em pipeline
- operandos são colocados em um registro vetorial para
serem processados na UAL
- Processador matricial x vetorial
- programação para o matricial voltada ao paralelismo
(+difícil)
- processador matricial é, em geral, mais rápido principalmente
para repetição de um mesmo processamento em vários "pedaços"
dos dados
- processador vetorial se adapta a processamentos paralelos e não
paralelos
- hardware do matricial é mais caro (muitas UALs)
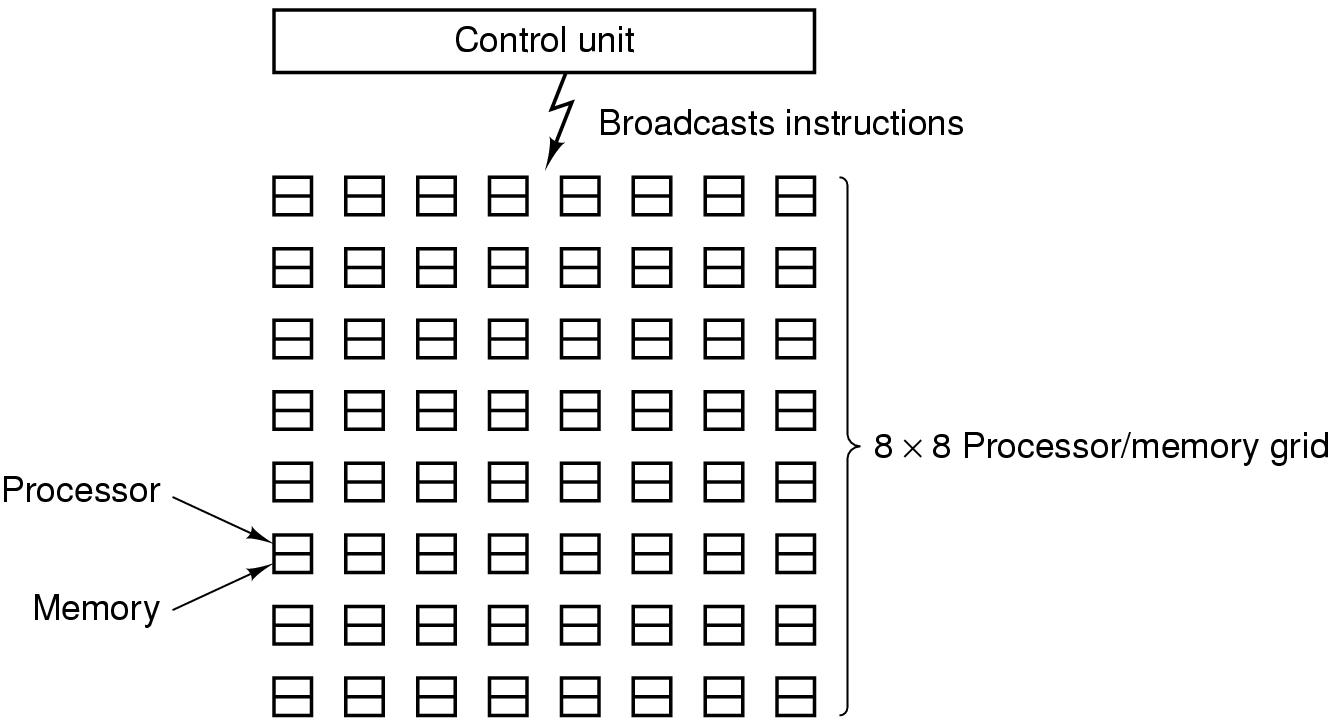
Figura 2-7: Processador Matricial do tipo ILLIAC IV
Problema: Os processadores matriciais não são
independentes pois compartilham uma única UC
Multiprocessadores
- é composto de vários processadores independentes
- compartilham uma mesma memória por um barramento principal
(veja figura 2.8(a))
- ou compartilham uma memória e tem memórias locais (veja
figura 2.8(b))
- executam processamentos locais
- liberam trafego do barramento principal
- é necessário gerenciar conflitos
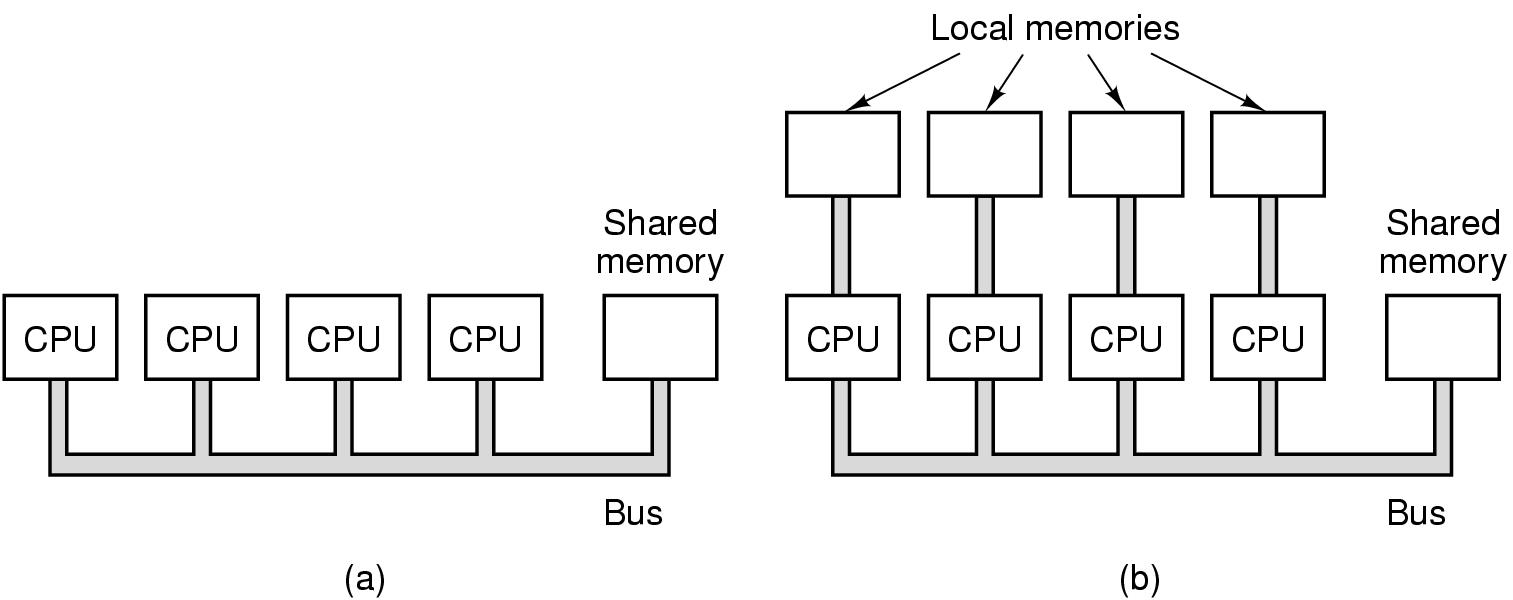
Figura 2-8: (a) Multiprocessador organizado em torno de um único
barramento. (b) Multicomputador com memórias locais.
Problema: Sistemas com muitos processadores (>64)
são de difícil implementação. Dificuldade
está na conexão dos processadores a memória.
Multicomputadores
- Sistemas com um grande número de computadores interconectados
- Não existe nenhum tipo de memória comum sendo compartilhada
- Comunicação entre computadores é feita através
de troca de mensagens a uma velocidade bem alta
- Computador pode não precisa estar ligados diretamente com todos
os outros (uso de topologias em árvore, anéis, etc..)
- Mensagens são roteadas do computador fonte para o destino (usando
computadores intermediários)
- Existem em operação sistemas multicomputadores com cerca
de 10000 computadores
Importante: Como sistemas multiprocessadores são mais fáceis
de programar e sistemas multicomputadores são mais fáceis de
construir, existem sistemas híbridos. Tais computadores
dão a ilusão de compartilhamento de memória, sem arcar
com o ônus de implementá-la diretamente.