Classificação de Imagens
O que é classificação?
- Classificação é o processo de extração de informação em imagens para reconhecer padrões e objetos homogêneos e
são utilizados em Sensoriamento Remoto para mapear áreas da superfície terrestre que correspondem aos temas de
interesse.
- A informação espectral de uma cena pode ser representada por uma imagem espectral, na qual cada "pixel" tem
coordenadas espaciais x, y e uma espectral L, que representa a radiância do alvo em todas as bandas espectrais, ou
seja para uma imagem de K bandas, existem K níveis de cinza associados a cada "pixel" sendo um para cada banda
espectral. O conjunto de características espectrais de um "pixel" é denotado pelo termo atributos espectrais.
- Os classificadores podem ser divididos em classificadores "pixel a pixel" e classificadores por regiões.
- Classificadores "pixel a pixel": Utilizam apenas a informação espectral de cada pixel para
achar regiões homogêneas. Estes classificadores podem ser separados em métodos estatísticos (utilizam regras da
teoria de probabilidade) e determinísticos (não utilizam probabilidade).
- Classificadores por regiões: Utilizam, além de informação espectral de cada "pixel", a
informação espacial que envolve a relação com seus vizinhos. Procuram simular o comportamento de um foto-
intérprete, reconhecendo áreas homogêneas de imagens, baseados nas propriedades espectrais e espaciais de
imagens. A informação de borda é utilizada inicialmente para separar regiões e as propriedades espaciais e
espectrais irão unir áreas com mesma textura.
- O resultado da classificação digital é apresentado por meio de classes espectrais (áreas que possuem
características espectrais semelhantes), uma vez que um alvo dificilmente é caracterizado por uma única assinatura
espectral. É constituído por um mapa de "pixels" classificados, representados por símbolos gráficos ou cores, ou
seja, o processo de classificação digital transforma um grande número de níveis de cinza em cada banda espectral
em um pequeno número de classes em uma única imagem.
- As técnicas de classificação aplicadas apenas a um canal espectral (banda da imagem) são conhecidas como
classificações unidimensionais. Quando o critério de decisão depende da distribuição de níveis de cinza em vários
canais espectrais as técnicas são definidas como de classificação multiespectral.
- O primeiro passo em um processo de classificação multiespectral é o treinamento. Treinamento é o reconhecimento
da assinatura espectral das classes. Existem basicamente duas formas de treinamento: supervisionado e não-
supervisionado.
- Quando existem regiões da imagem em que o usuário dispõe de informações que permitem a identificação de uma classe de interesse, o treinamento é dito supervisionado. Para um treinamento supervisionado o usuário deve identificar na imagem uma área representativa de cada classe. É importante que a área de treinamento seja uma amostra homogênea da classe respectiva, mas ao mesmo tempo deve-se incluir toda a variabilidade dos níveis de cinza. Recomenda-se que o usuário adquira mais de uma área de treinamento, utilizando o maior número de informações disponíveis, como trabalhos de campo, mapas, etc. Para a obtenção de classes estatisticamente confiáveis, são necessários de 10 a 100 "pixels" de treinamento por classe. O número de "pixels" de treinamento necessário para a precisão do reconhecimento de uma classe aumenta com o aumento da variabilidade entre as classes.
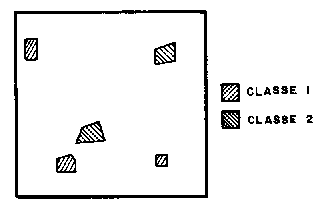
Exemplo de seleção de áreas no treinamento supervisionado.
Quando o usuário utiliza algoritmos para reconhecer as classes presentes na imagem, o treinamento é dito
não-supervisionado. Ao definir áreas para o treinamento não-supervisionado, o usuário não deve se preocupar com a
homogeneidade das classes. As áreas escolhidas devem ser heterogêneas para assegurar que todas as possíveis classes
e suas variabilidades sejam incluídas. Os "pixels" dentro de uma área de treinamento são submetidos a um algoritmo
de agrupamento ("clustering") que determina o agrupamento do dado, numa feição espacial de dimensão igual ao número
de bandas presentes. Este algoritmo assume que cada grupo ("cluster") representa a distribuição de probabilidade
de uma classe.
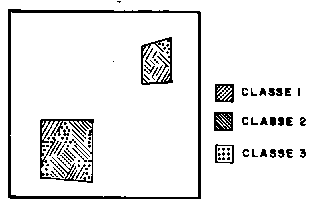
Exemplo de seleção de áreas no treinamento não-supervisionado.
- As técnicas de classificação multiespectral "pixel a pixel" mais comuns são: máxima verossimilhança (MAXVER),
distância mínima e método do paralelepípedo.
- MAXVER é o método de classificação, que considera a ponderação das distâncias entre médias dos níveis digitais
das classes, utilizando parâmetros estatísticos.
- Os conjuntos de treinamento definem o diagrama de dispersão das classes e suas distribuições de probabilidade,
considerando a distribuição de probabilidade normal para cada classe do treinamento.
- Para duas classes (1 e 2) com distribuição de probabilidade distintas, as distribuições representam a
probabilidade de um "pixel" pertencer a uma ou outra classe, dependendo da posição do "pixel" em relação a esta
distribuição. Ocorre uma região onde as duas curvas sobrepõem-se, indicando que um determinado "pixel" tem igual
probabilidade de pertencer às duas classes. Nesta situação estabelece-se um critério de decisão a partir da
definição de limiares.
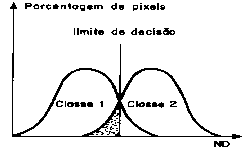
Exemplo de limite de aceitação de uma classificação, no ponto onde as duas distribuições se cruzam. Um "pixel"
localizado na área sombreada, apesar de pertencer à classe 2, será classificado como classe 1.
- O limiar de aceitação indica a % de "pixels" da distribuição de probabilidade de uma classe que será
classificada como pertencente a esta classe. Um limite de 99%, por exemplo, engloba 99% dos "pixels", sendo que
1% serão ignorados (os de menor probabilidade), compensando a possibilidade de alguns "pixels" terem sido
introduzidos no treinamento por engano, nesta classe, ou estarem no limite entre duas classes. Um limiar de 100%
resultará em uma imagem classificada sem rejeição, ou seja, todos os "pixels" serão classificados.
- Para diminuir a confusão entre as classes, ou seja, reduzir a sobreposição entre as distribuições de
probabilidades das classes, aconselha-se a aquisição de amostras significativas de alvos distintos e a avaliação
da matriz de classificação das amostras.
- A matriz de classificação apresenta a distribuição de porcentagem de "pixels" classificados correta e
erroneamente. No exemplo a seguir, apresenta-se uma matriz de classificação com as porcentagens de 4 classes
definidas na aquisição de amostras, os valores de desempenho médio, abstenção (quanto não foi classificado) e
confusão média.
|
N |
1 |
2 |
3 |
4 |
1 |
4.7 |
94.3 |
0.0 |
0.0 |
0.9 |
2 |
1.1 |
0.0 |
82.3 |
0.0 |
16.6 |
3 |
0.0 |
13.3 |
0.0 |
86.7 |
0.0 |
4 |
3.8 |
0.0 |
4.7 |
0.0 |
91.5 |
- Desempenho médio: 89.37
- Abstenção média: 3.15
- Confusão média: 7.48
- O valor de N representa a quantidade de cada classe (porcentagem de "pixels") que não foi classificada.
- A classe 1 corresponde à floresta, a classe 2 ao cerrado, a classe 3 ao rio e a classe 4 ao desmatamento.
- Uma matriz de classificação ideal deve apresentar os valores da diagonal principal próximos a 100%, indicando
que não houve confusão entre as classes. Contudo esta é uma situação difícil em imagens com alvos de
características espectrais semelhantes.
- O valor fora da diagonal principal, por exemplo 13.3 (classe linha 3 e coluna 1), significa que 13.3% da área
da classe "rio" amostrada foi classificada como classe 1 (floresta). O mesmo raciocínio deve ser adotado para os
outros valores.
- Para diminuir a confusão entre as classes, aconselha-se a análise das amostras.
| |
Amostras |
Classes |
1 |
2 |
3 |
Floresta |
90 |
50 |
87 |
Cerrado |
5 |
50 |
0 |
Rio |
5 |
0 |
0 |
Desmatamento |
0 |
0 |
10 |
- Os valores em porcentagem indicam que na amostra 1, 90% dos "pixels" são classificados como floresta, 5% como
cerrado e 5% como rio, o que resulta em uma amostra confiável. Por sua vez, a amostra 2 apresentou uma confusão de
50% entre as classes floresta e cerrado, indicando que esta deve ser eliminada.
O que é o classificador MAXVER-ICM?
- Enquanto o classificador MAXVER associa classes considerando pontos individuais da imagem, o classificador
MAXVER-ICM (Interated Conditional Modes) considera também a dependência espacial na classificação.
- Em uma primeira fase, a imagem é classificada pelo algoritmo MAXVER atribuindo classes aos "pixels",
considerando os valores de níveis digitais. Na fase seguinte, leva-se em conta a informação contextual da imagem,
ou seja a classe atribuída depende tanto do valor observado nesse "pixel", quanto das classes atribuídas aos seus
vizinhos.
- O algoritmo atribui classes a um determinado "pixel", considerando a vizinhança interativamente. Este processo
é finalizado quando a % de mudança (porcentagem de "pixels" que são reclassificados) definida pelo usuário é
satisfeita. O SPRING fornece ao usuário as opções de 5%, 1% e 0.5% para valores de porcentagem de mudanças. Um
valor 5% significa que a reatribuição de classes aos "pixels" é interrompida quando apenas 5% ou menos do total
de "pixels" da imagem foi alterado.
O que é classificação por distância euclidiana?
- O método de classificação por distância Euclidiana é um procedimento de classificação supervisionada que
utiliza esta distância para associar um "pixel" a uma determinada classe.
- No treinamento supervisionado, definem-se os agrupamentos que representam as classes. Na classificação, cada
"pixel" será incorporado a um agrupamento, através da análise da medida de similaridade de distância Euclidiana,
que é dada por:
d (x,m) = (x2 - m2) 1/2
onde:
- x = "pixel" que está sendo testado
- m = média de um agrupamento
- N = número de bandas espectrais
- O classificador compara a distância Euclidiana do "pixel" à média de cada agrupamento. O "pixel" será
incorporado ao agrupamento que apresenta a menor distância Euclidiana. Este procedimento é repetido até que toda
a imagem seja classificada.
O que é pós-classificação?
- Aplica-se este procedimento em uma imagem classificada, com o objetivo de uniformizar os temas, ou seja,
eliminar pontos isolados, classificados diferentemente de sua vizinhança. Com isto, Gera-se um imagem classificada
com aparência menos ruidosa.
- Em uma janela de 3 x 3 "pixels", o ponto central é avaliado quanto à freqüência das classes (temas), em sua
vizinhança. De acordo com os valores de peso e limiar definidos pelo usuário, este ponto central terá ou não sua
classe substituída pela classe de maior freqüência na vizinhança.
- O peso varia de 1 a 7 e define o número de vezes que será considerada a freqüência do ponto central.
- O limiar varia também de 1 a 7 e é o valor de freqüência acima do qual o ponto central é modificado.
- Por exemplo, para a janela de uma imagem classificada será avaliado o "pixel" central pertencente à classe 2.
Considera-se um peso e um limiar iguais a 3.
- Obtém-se a seguinte freqüência de classes:
Classe |
1 |
2 |
3 |
5 |
Freqüência |
1 |
3 |
3 |
4 |
- A tabela acima indica que a classe 1 ocorre uma vez; a classe 3 ocorre três vezes e a classe 5, quatro vezes. A
freqüência da classe 2 é considerada 3, pelo fato do peso definido ser 3. O limiar igual a 3 fará com que o ponto
central (de classe 2) seja atribuído à classe 5, cuja freqüência (4) é maior que o limiar definido.
- A janela classificada com seus temas uniformizados torna-se:
- A definição de peso e limiar dependerá da experiência do usuário e das características da imagem classificada.
Quanto menor o peso e menor o limiar, maior o número de substituições que serão realizadas.
|











